Доступ к базе данных на стороне клиента
Видимо, наиболее мощные средства обеспечения доступа к базам данных на стороне Web-клиента обеспечивает язык Java. Java - это объектно-ориентированный язык программирования, являющийся, по сути дела, "безопасным" подмножеством языка С++. В частности, Java не содержит средств адресной арифметики, не поддерживает механизм множественного наследования и т. д. Поэтому утверждается, что корректность Java-программы можно проверить до ее реального выполнения (это абсолютно недоказанное утверждение). Различают:
язык Java, как таковой, для которого существуют компиляторы в так называемый "мобильный код" (машинно-независимый код, который может интерпретироваться или из которого могут генерироваться машинные коды на разных платформах);
язык JavaScript, который обычно используется для расширения возможностей языка HTML за счет добавления процедурной составляющей;
и программный продукт HotJava, являющийся, по сути, интерпретатором мобильных кодов Java.
Для обеспечения доступа к базам данных на стороне Web-клиента наиболее существенно наличие языка Java. Технология разработки HTML-документа позволяет написать произвольное количество дополнительных Java-программ, откомпилировать их в мобильные коды и поставить ссылки на соответствующие коды в теле HTML-документа. Такие дополнительные Java-программы называются апплетами (Java-applets). Получив доступ к документу, содержащему ссылки на апплеты, клиентская программа просмотра запрашивает у Web-сервера все мобильные коды. Коды могут начать выполняться сразу после размещения в компьютере клиента или быть активизированы с помощью специальных команд.

Поскольку апплет представляет собой произвольную Java-программу, то, в частности, он может быть специализирован для работы с внешними базами данных. Более того, система программирования Java включает развитый набор классов, предназначенных для поддержки графического пользовательского интерфейса. Опираясь на использование этих классов, апплет может получить от пользователя информацию, характеризующую его запрос к базе данных, в том же виде, как если бы использовался стандартный механизм форм языка HTML, а может применять какой-либо другой интерфейс.
Для взаимодействия Java-апплета с внешним сервером баз данных разработан специализированный протокол JDBC, который, фактически, сочетает функции шлюзования между интерпретатором мобильных Java-кодов и ODBC, а также включает ODBC.
В заключение сравним достоинства и недостатки двух рассмотренных подходов. Использование CGI-скриптов на стороне Web-сервера позволяет иметь на стороне клиента только сравнительно простые программы просмотра. Вся хитроумная логика работы с базами данных (возможно, с обработкой полученных данных) переходит на сторону Web-сервера. Это легкий способ построения трехзвенной архитектуры приложения. (В последнее время разгрузку клиента от логики приложения называют решением проблемы "толстого" клиента. В данном случае мы можем иметь предельно тонкого клиента при утолщении сервера.) Отрицательным моментом является то, что при необходимости подключения нового CGI-скрипта, вообще говоря, требуется (относительная) модификация кода сервера.
Использование Java-апплетов, вообще говоря, обеспечивает более гибкое решение. Апплет - это часть HTML-документа. Для включения нового апплета нужно всего-навсего перекомпоновать документ. Web-cервер трогать не нужно. С другой стороны, клиент должен быть толще. Что бы там не говорили, клиент должен быть достаточно "толстым", чтобы в приемлемое время справиться с интерпретацией всех апплетов. Но, конечно же, сервер по-прежнему должен быть "толще" клиента.
На самом деле и при применении первого подхода, и при использовании второго остается нерешенной одна организационно-производственная проблема: кто должен проектировать, писать, отлаживать и сопровождать процедурный код? Web-мастера, производящие HTML-документы, обычно считают себя, скорее, дизайнерами нежели программистами. А здесь требуется чисто программистская работа. Иметь же двух мастеров на одном Web-site - это недопустимая роскошь. Придется растить людей, обладающих достаточными эстетическими способностями и являющимися в то же время квалифицированными и ответственными программистами.
Доступ к базе данных на стороне сервера
Механизм реализуется за счет наличия двух средств: включением форм в документ, составленный с использованием языка HTML и использования внешних по отношению к серверу Web программ. Клиентская часть приложения взаимодействует с серверной частью через специфицированный протокол CGI (Common Gateway Interface) или внедренный позже API (Application Program Interface). (Хотя CGI называется "общим интерфейсом шлюзования", по сути дела, это одновременно некоторое подмножество протокола HTTP, и способ его соблюдения при взаимодействии сервера с внешней программой.)
При реализации на основе CGI общая схема реализации доступа к базе данных на стороне Web-сервера выглядит следующим образом:
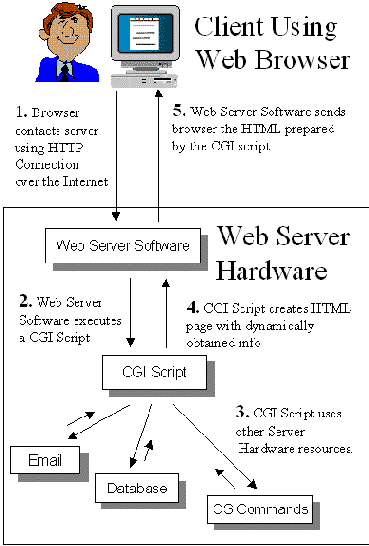 |
Просматривая документ клиент встречает форму, которая предназначена для ввода параметров запроса данных из базы. Клиент заполняет форму и отправляет ее на сервер.
Получив заполненную форму, сервер запускает соответствующую внешнюю программу, передавая ей параметры и получая результаты на основе протокола CGI. Внешняя программа преобразует запрос, выраженный с помощью заполненной формы, в запрос на языке, понятном серверу баз данных (обычно это язык SQL). После получения результатов запроса внешняя программа формирует соответствующую виртуальную или реальную HTML-страницу, передает ее серверу и завершает свое выполнение. Сервер передает сформированную HTML-страницу клиенту, и на этом процедура доступа к базе данных завершается. |
На сленге Web-мастеров любая внешняя программа, запускаемая Web-сервером в соответствии со спецификациями CGI, называется CGI-скриптом. CGI-скрипт может быть написан на языке программирования (С, С++, Pascal и т. д.) или на командном языке (языки семейства shell, perl и т. д.). CGI-скрипт, выполняющий роль посредника между Web-сервером и другими видами серверов (например сервером баз данных), называется шлюзом (видимо, более правильно было бы использовать термин CGI-шлюз). Наличие CGI-скриптов на стороне Web-сервера позволяет, в частности, перенести часть логики приложения из клиента на сервер. CGI-шлюзы представляют собой средство для организации трехзвенной (в общем случае, многозвенной) архитектуры клиент-сервер.
В спецификациях CGI предусмотрены следующие способы взаимодействия Web-сервера и CGI-скрипта (по крайней мере в среде ОС Unix):
Первый способ состоит в использовании создаваемых сервером переменных окружения, через которые передается как общая информация, независящая от функциональных особенностей CGI-скрипта (например имя и версия Web-сервера), так и специфические данные, определяющие поведение CGI-скрипта (скажем набор значений, введенных в форму на стороне клиента).
Второй способ заключается в формировании параметров argc и argv, которые передаются функции main CGI-скрипта (как если бы CGI-скриптвызывался командной строкой в интерактивном режиме). Этот способ применяется для реализации ограниченного класса запросов ISINDEX.
Наконец, входные параметры могут передаваться CGI-скрипту через файл стандартного ввода, а CGI-скрипт может передавать Web-серверу результирующие данные через файл стандартного вывода.
Как видно, при использовании CGI вся интерпретация пользовательского запроса производится CGI-скриптом. Скрипт может быть предельно жестким, ориентированным на выполнение запроса к фиксированной таблице фиксированной базы данных, или относительно гибким, способным выполнить произвольный запрос к одной или нескольким таблицам базы данных, идентифицируемой в параметрах клиента.
Что касается API, то для людей, знающих одновременно Unix и операционные системы вообще, ситуация предельно ясна. Запуск независимого "тяжеловесного" процесса стоит немало. Загрузка и выполнение еще одной программы в уже существующем адресном пространстве по сравнению с предыдущем вариантом гораздо дешевле. Нет никаких новых идей. API - это, фактически, дешевый способ (хотя и небезопасный: понятно, почему?) выполнить в адресном пространстве сервера WWW программу, которая соответствует спецификациям на языке HTML (объясняю, почему; никто не захочет впустить в свою квартиру на предмет хотя бы временного жительства незнакомого человека; внешние программы незнакомы серверу). Такая программа должна быть заранее подготовлена и включена в библиотеку, из которой сервер может производить динамическую загрузку (например, такая библиотека может быть разделяемой - shared library). Т. е. смысл не меняется, меняется только реализация.
Курс Разработчик приложений Web баз данных
GET метод является наиболее простым и быстрым методом передачи запросов. Минимум, что должен содержать запрос, который использует GET метод - это имя метода, URL путь, и символ начала новой строки (<NL>) :
GET URL_path <NL>
Полная форма GET запроса должна содержать еще и версию протокола, значения полей HTTP (содержащих информацию о клиенте или самом запросе), как показано ниже:
GET /waite/newbooks/search?keyword=web HTTP/1.0
Accept:text/*; image/jpeg
Host: www.mcp.com:80
If-Modified-Since: Friday, 15-Aug-97 02:12:28 GMT
User-Agent: Mozilla/3.0Gold (Win95; I)
<NL>
В данном примере, HTTP/1.0 - это версия протокола, а Accept, Host, If-Modified-Since и User-Agent -четыре заголовка полей HTTP, которые передаются вместе с GET запросом.
- Контрольный вопрос
Укажите название поля HTTP значение которого позволяет определить хост посетителя HTML страницы.
HTTP методы запроса
HTTP обеспечивает несколько методов запроса. Зачастую используют GET и POST методы, которые поддерживает большинство браузеров.
Инициализация методов запроса браузером
Следующие события всегда заставляют Web браузер посылать запрос:
после щелчка пользователя на ссылке HTML документа. Ссылку создают используя якорь, как показано ниже:
<A HREF="URL">Текст ссылки</A>
после ввода URL в адресной строке браузера;
в результате передачи формы HTML методом GET или POST, как показано ниже:
<FORM ACTION="URL" METHOD="POST">
Использование расширения пути и строки запроса для передачи данных
Вы уже знаете, что запрос состоит из URL_path и полей HTTP заголовка, которые Web браузер создает автоматически при посылке запроса. Единственная часть, которой вы управляете в получающемся запросе - URL_path. Хотя основная цель URL_path - указать расположение запрошенного информационного ресурса, но она не единственная. Реально URL_path состоит из следующих трех частей:
адреса документа;
расширения пути, которое указывают после пути для описания дополнительной информации;
строки запроса, которая следует за знаком "?".
Например,
/calendar/view.exe/sales?fromdate=10/1/99&todate=12/31/99
В этом примере /calendar/view.exe - путь, /sales расширение пути, a fromdate=10/1/99&todate=12/31/99 - строка запроса URL_path. Путь определяет местоположение CGI программы VIEW.EXE, которая выберет среди продаж только те, которые были сделаны в период с 10/1/99 по 12/31/99.
[<< ] | [] | [ >>]
Коммуникационная модель Web
В основе World Wide Web лежит модель связи, состоящая из двух основных элементов - Web клиента и Web сервера. В этой клиент-серверной модели Web клиент (обычно Web браузер) сначала инициализирует соединение с нужным Web сервером и затем посылает запрос. Web сервер принимает запрос обрабатывает его и отправляет результат клиенту.
Схематично взаимодействие клиента с сервером можно изобразить так

Литература и ресурсы
Selena Sol. Introduction to Databases for the Web - http://www.stars.com/Authoring/DB/Intro/
Кузнецов С.Д. Доступ к базам данных с использованием технологии WWW - http://www.citforum.ru/internet/articles/art_5.shtml
POST метод
Метод POST позволяет HTTP запросу нести дополнительные данные наряду с URL путем и полями заголовка, как показано в следующем примере:
POST /cgi-win/wdbic/test/test.exe HTTP/1.0
<NL>
Accept:text/*; image/jpeg
Host: localhost
If-Modified-Since: Friday, 15-Aug-97 02:12:28 GMT
User-Agent: Mozilla/3.0Gold (Win95; I)
Content-type: application/x-www-form-urlencoded
Content-length: 11
<NL>
keyword=web
Поля сontent-type и content-length описывают формат и размер дополнительных данных. Эти дополнительные данные обычно использует информационный запрашиваемый ресурс, которым является исполняемая программа (в данном примере это /cgi-win/wdbic/test/test.exe). Их пересылают на Web сервер для обработки исполняемой программой.
Universal Resource Locator
Universal Resource Locator (URL) - текстовая строка, которая уникально идентифицирует информационный ресурс. Другими словами, он определяет адрес искомых данных. Синтаксис URL:
протокол://хост[:порт]/URL_path
Пример URL
http://www.mcp.com:80/waite/newbooks/search?keyword=web
Тип протокола (http) определяет метод связи, который необходим для передачи документа. Кроме http протокола существует ftp (File Transfer Protocol), file (для файлов, хранящихся на локальном компьютере), telnet (для telnet сессии), mailto
(для Internet почты) и news (для Usenet новостей).
Хост (www.mcp.com) - это реальный домен Internet или IP адрес, представляемый комбинацией чисел десятичного формата. Порт (80) – список TCP портов, который используют для установки соединения.
URL_path (/waite/newbooks/search?keyword=web) указывает местоположение запрашиваемой информации на хост сервере.
Web протоколы
Как показано на рисунке, передача данных между Web клиентом и Web сервером на основе трех протоколов связи: TCP/IP, HTTP и HTML. Каждый протокол функционирует в собственном независимом уровне.
Transmission Control Protocol/Internet Protocol (TCP/IP) - протокол, который поддерживают все компьютеры, соединенные с Internet и обеспечивает достоверную передачу данных между компьютерами Internet.
Hypertext Transfer Protocol (HTTP) - стандарт транзакции (общения) между Web клиентом и Web сервером. Другими словами, правил, которые определяют начало и окончание передачи запроса, а так же адреса требуемого документа. Принятый в HTTP метод стандартной адресации документа (universal resource locator - URL) позволяет достичь максимальной эффективности связи за счет минимизации транзакции между сервером и клиентом (сравните с FTP протоколом, где адресацию файлов реализуют в командном режиме).
По сути HTTP превращает Internet (сеть сетей) в Web или WWW (World Wide Web - "Всемирная паутина") - сеть документов.
Hypertext Markup Language (HTML) - стандарт, в соответствии с которым автор разрабатывает документ, чтобы представить информацию Web клиенту. HTML применяют не только для отображения текста, изображений и гиперссылок, но и создания интерактивных Web приложений.
Хотя HTML и HTTP разработаны, чтобы работать на независимых уровнях, HTML присущи некоторые особенности, которые отражают близкую связь с HTTP. Среди этих унаследованных черт, два ярких - использование URL для определения ссылок и поддержка методов запроса.
[] | [ >>]
